Datacenters in space: how FPGAs compute through a particle storm
The idea sounded like science fiction five years ago; now it has funding rounds and launch manifests. Orbital datacenters promise sunlight that never sets on your solar array, free-ish cooling into deep space, and compute parked next to the satellites that generate the data. Starcloud has flown GPU hardware to orbit, Google's Project Suncatcher is exploring TPU constellations, China's Three-Body Computing Constellation began launching in 2025, and ESA's ASCEND study costed out gigawatt-class orbital compute for Europe.
Between the press releases and the physics sits one inconvenient particle at a time: space is a radiation environment, and radiation flips bits. How you compute reliably up there is a solved-but-subtle engineering discipline in which FPGAs — the right FPGAs, used the right way — have starred for decades. Every trick the orbital datacenter builders need was pioneered by satellite payload designers, and it's a genuinely beautiful corner of our field.
What the radiation actually is
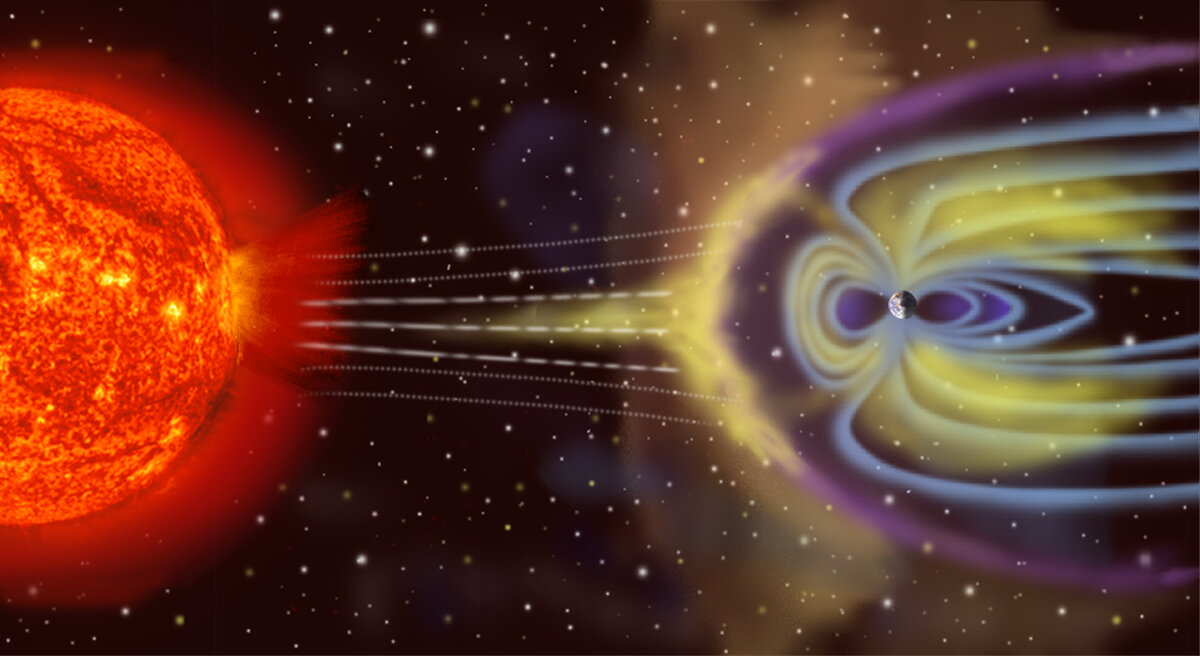 The solar wind meeting Earth's magnetic field — most charged particles
deflect around us; some get trapped. Artist's rendition: NASA (public
domain).
The solar wind meeting Earth's magnetic field — most charged particles
deflect around us; some get trapped. Artist's rendition: NASA (public
domain).
Three populations matter:
- Trapped particles — protons and electrons held in the Van Allen belts; low-Earth orbits graze them, especially through the South Atlantic Anomaly.
- Solar particle events — flares and coronal mass ejections that raise the particle flux by orders of magnitude for hours or days.
- Galactic cosmic rays — high-energy heavy ions from outside the solar system: rare, but each one is a wrecking ball no practical shielding stops.
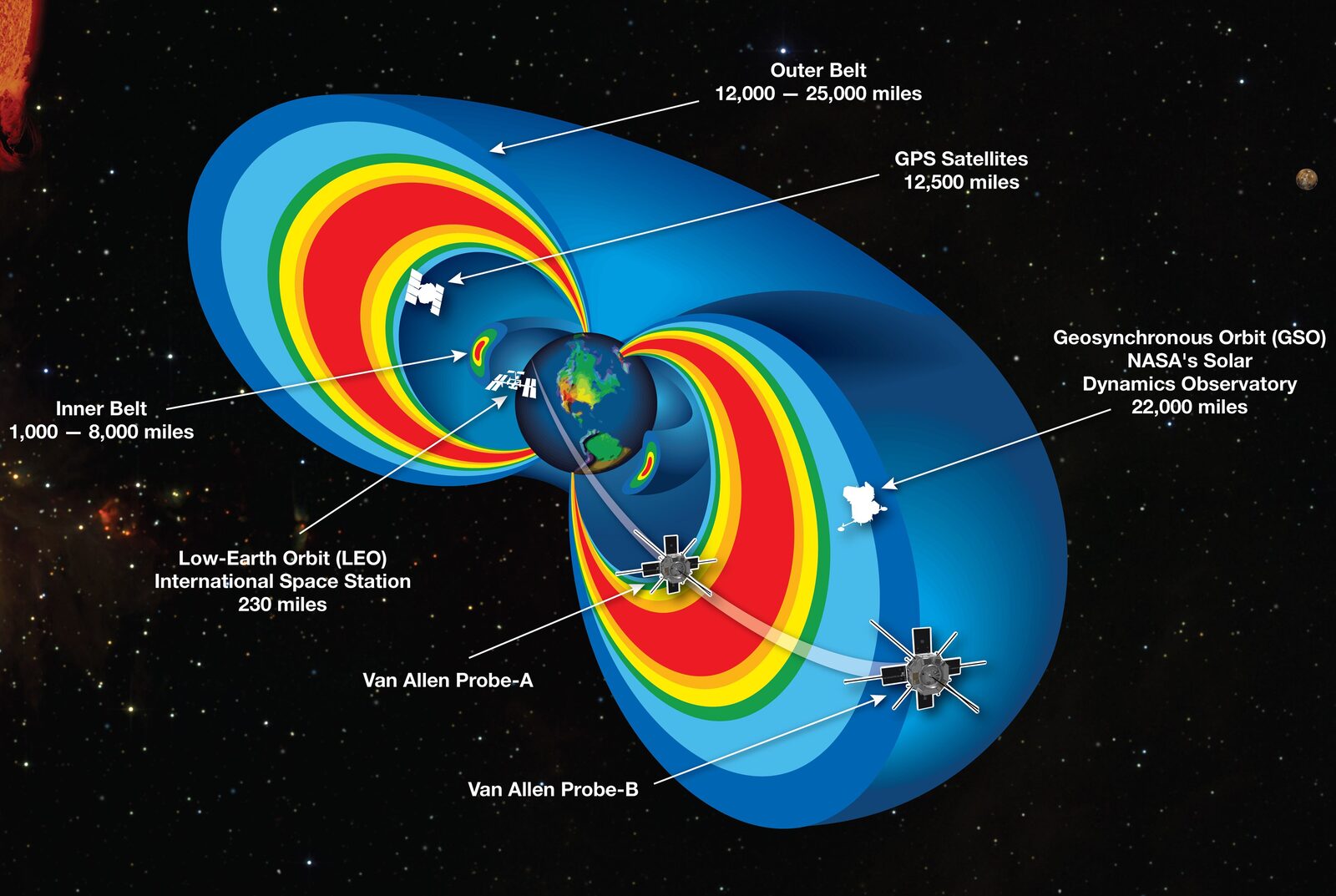 The Van Allen belts in cutaway, with the ISS (LEO), GPS and
geosynchronous orbits marked — every orbit picks its own radiation
diet. Illustration: NASA (public domain).
The Van Allen belts in cutaway, with the ISS (LEO), GPS and
geosynchronous orbits marked — every orbit picks its own radiation
diet. Illustration: NASA (public domain).
Their effects on electronics split into two families. Total ionizing dose (TID) is cumulative — the slow drift of transistor thresholds over years, rated in krad. Single-event effects (SEE) are instant: one particle deposits charge in one spot and something happens right now. The SEE family includes destructive members (single-event latch-up, where a parasitic thyristor turns on and cooks the die unless power is cycled) and the star of this article: the single-event upset.
The SEU, and why SRAM FPGAs feel it twice
An SEU is a bit flip. A particle track deposits charge on a storage node; if it exceeds the cell's critical charge, the latch changes state. In a CPU that corrupts data. In an SRAM-based FPGA it can corrupt something more interesting — because the configuration memory that defines the circuit is itself SRAM:

Flip a data bit in a BRAM and you have a wrong value. Flip a configuration bit and a LUT's truth table changes, or a routing switch connects two nets that were never supposed to meet. The circuit you verified is no longer the circuit that's running. Modern parts hold hundreds of megabits of configuration, and in LEO a commercial SRAM FPGA collects config upsets at rates measured in upsets per device-day — each one a tiny, random act of redesign.
That sounds like disqualification. It's actually just a requirements spec, and the industry has three great answers to it.
Answer 1: make the cell immune
Radiation-hardened-by-design parts change the storage cell itself. Flash- and antifuse-configured FPGAs (Microchip's RTG4 and RT PolarFire lines descend from this philosophy) hold their configuration in cells that particle strikes essentially can't flip — the circuit is safe, and only your application data needs protecting. RHBD SRAM parts like the classic Virtex-5QV and Europe's NanoXplore NG-Ultra harden the latches with interlocked cell designs. The trade: hardened parts trail commercial silicon by generations in density and speed, and cost what flight heritage costs.
Answer 2: outvote and repair the upset
The NewSpace move is to fly commercial silicon and win with architecture — which is where the classic techniques shine:

Triple modular redundancy (TMR) instantiates the logic three times and votes 2-of-3 on every result: one upset in one copy is outvoted, masked completely. Configuration scrubbing continuously reads back the configuration memory, checks it (frame ECC plus a golden image), and rewrites any corrupted frame — typically in milliseconds-to-seconds loops, via dedicated silicon like the SEM controller on AMD/Xilinx parts.
The two are partners with a lovely reliability equation. TMR fails only if a second upset lands in a different copy of the same voting domain before the scrubber repairs the first. For a per-domain upset rate λ and scrub period T, that double-hit probability goes as 3(λT)² — quadratically small. Concretely: a device collecting ~2 config upsets per day, partitioned into 100 voting domains and scrubbed every 10 seconds, sees λT ≈ 2×10⁻⁶ per domain per scrub window — a mean time to voter defeat in the tens of thousands of years. Radiation didn't get gentler; the math got ruthless on our behalf.
The supporting cast matters too: ECC on every BRAM (built into modern
blocks), EDAC on external DRAM, watchdogs that catch single-event
functional interrupts, current-limit circuits that power-cycle latch-ups
before they're fatal, and safe state-machine
encodings where illegal states route to recovery
instead of undefined behavior — the default: branch in our FSM
skeletons is a radiation-tolerance feature wearing a code-style hat.
Answer 3: accept failures, architect the fleet
The datacenter-scale insight is that terrestrial cloud thinking and space thinking converge: assume nodes fail, checkpoint, replicate, reschedule. Starlink demonstrated that thousands of COTS-heavy satellites with system-level redundancy can out-deliver a handful of exquisite ones, and orbital-compute ventures flying commercial GPUs lean on shielding, ECC, checkpointing and job-level retry rather than rad-hard silicon. A GPU that occasionally SEFIs and reboots is acceptable when the orchestrator treats it like any preempted worker.
Where do FPGAs sit in that architecture? Everywhere the failure can't be casual: the downlink modems and their CRC/FEC pipelines, the storage controllers doing EDAC, the network fabric between compute nodes, power management, and the supervisory logic that reboots the GPUs — the deterministic, always-correct layer that makes "let it crash" safe for everything above it. Radiation-tolerant FPGA families (the space-grade Versal class) now bring serious DSP and AI throughput to that trusted layer, so increasingly the FPGA is also doing the inference on the sensor data, not just moving it (the FPGAs-for-AI economics get even better when every watt is solar and every gram costs launch fuel).
The part you can practice today
Here's the fun secret: SEU mitigation is just digital design with the stakes turned up, and every technique in this article is buildable with what's on this site. Triplicate a counter from the course and write a voter; the playground's new synth button will show you TMR's honest 3.2x cost. Generate a CRC and you've built the heart of a scrubber's frame check. Give your FSM a recovery-safe default. The engineers keeping computers alive in the Van Allen belts are using the same building blocks you already have open in another tab — just pointed at a sky full of particles.